 This is my from-scratch implementation of the original transformer architecture from the following paper: Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems. 2017.
This is my from-scratch implementation of the original transformer architecture from the following paper: Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems. 2017.
My Code Implementation: Kaggle
If you wanna quickly try out the attention model from the parallel text examples, then checkout this : Link . But I recommend you implement the above main Kaggle code.

Table of Contents:
- Introduction
- Pre-requisites
- Architecture Overview
- Implementation Details
- Training
- Evaluation
- Use Cases / Dataset
- References
1. Introduction 📘
The Transformer model, proposed in the paper "Attention Is All You Need", eliminates the need for recurrent architectures (RNNs) and instead uses a self-attention mechanism to process sequential data. This allows the model to better capture relationships within data and enables parallelization, significantly improving training efficiency.
In this repository, I implement the core ideas presented in the paper and provide a clear walkthrough of how to implement and train the Transformer for various NLP tasks.
2. Pre-requisites 🛠️
Before running the implementation, ensure you have the following dependencies:
- Python 3.x
- TensorFlow / PyTorch (depending on your preference)
- NumPy
- Matplotlib (for visualizations)
- scikit-learn (for model evaluation)
You can install the required dependencies by running:
pip install -r requirements.txt3. Architecture Overview 🏗️
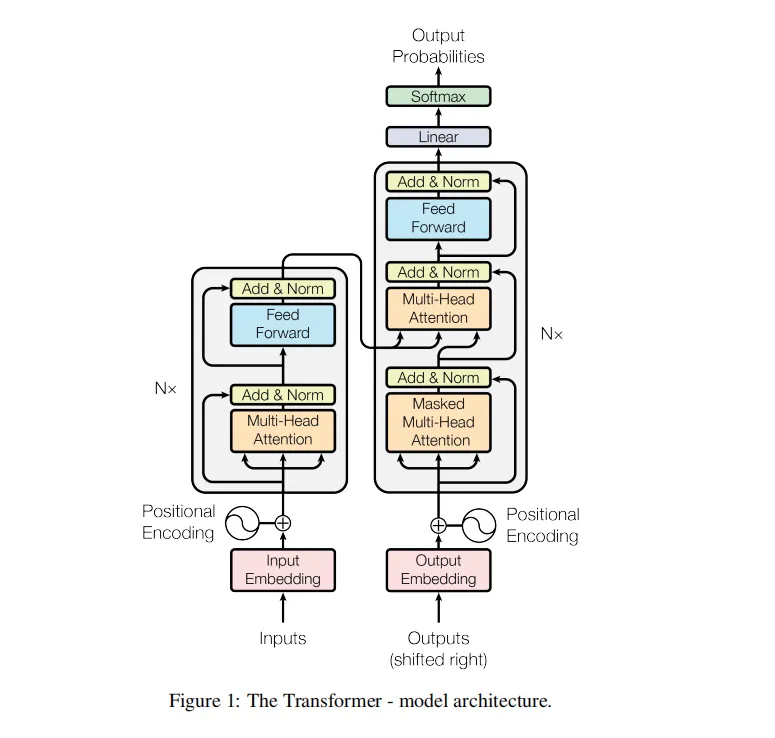
The architecture of the Transformer model consists of two main parts: the Encoder and the Decoder. Both of these components use stacked layers of multi-head self-attention and position-wise feedforward networks.
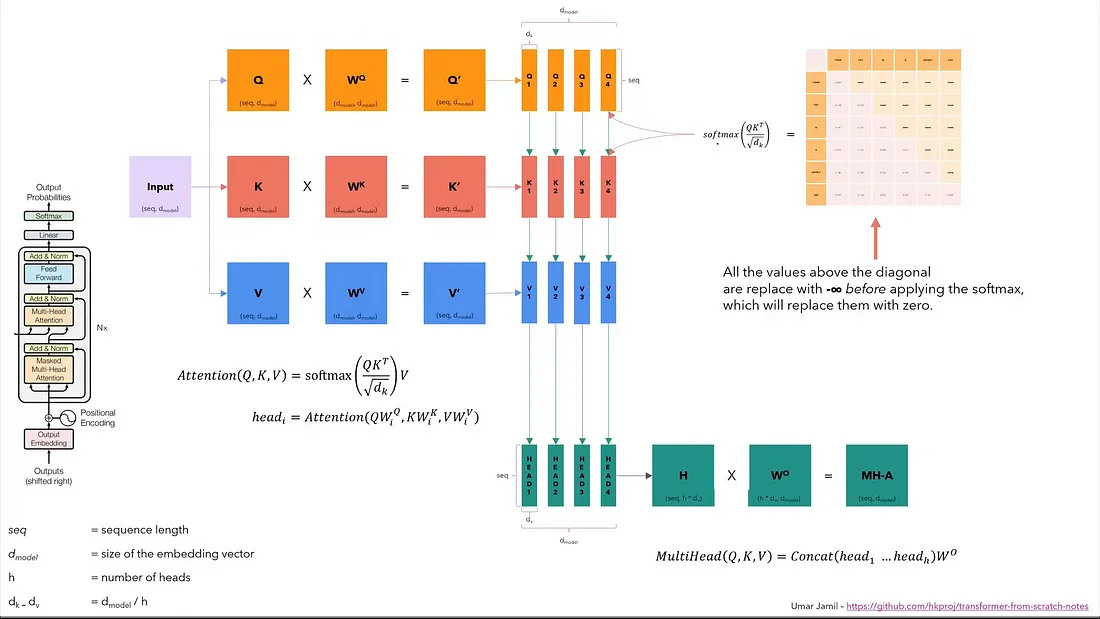
Key Components:
-
Self-Attention: Helps the model focus on different parts of the input sequence when encoding/decoding.
-
Positional Encoding: Adds information about the relative positions of words in the sequence.
-
Multi-Head Attention: Multiple attention mechanisms run in parallel, allowing the model to learn from different aspects of the input data simultaneously.
-
Feedforward Networks: Simple neural networks that process each token individually after the attention layer.
4. Implementation Details 🧩
The implementation is based on the architecture described in the paper and follows these key steps:
a. Input Processing:
- Tokenization of input text.
- Conversion of tokens to embeddings.
- Adding positional encoding to token embeddings.
b. Encoder Layer:
- Multi-Head Self-Attention.
- Add & Normalize.
- Position-Wise Feedforward Networks.
c. Decoder Layer:
- Multi-Head Self-Attention.
- Encoder-Decoder Attention.
- Position-Wise Feedforward Networks.
d. Final Output:
- Linear layer with SoftMax activation for generating the output sequence.
The entire model can be built using either TensorFlow or PyTorch. You can switch between frameworks by selecting the appropriate implementation.
5. Training 🏋️♂️
The Transformer model is trained using supervised learning on large-scale datasets (e.g., language translation). The training process involves:
- Loss Function: Categorical Cross-Entropy Loss.
- Optimization: Adam optimizer with learning rate scheduling.
- Metrics: Perplexity and BLEU score for language translation tasks.
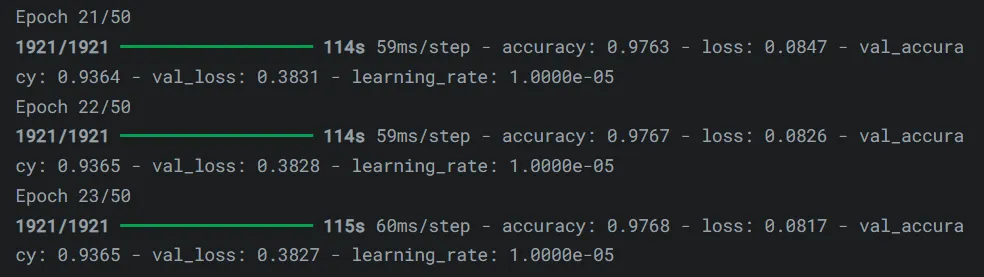
6. Evaluation 📊
After training, evaluate the model’s performance on validation and test datasets. The evaluation script calculates metrics such as:
- BLEU Score: For machine translation tasks.
- Perplexity: For language modeling tasks.
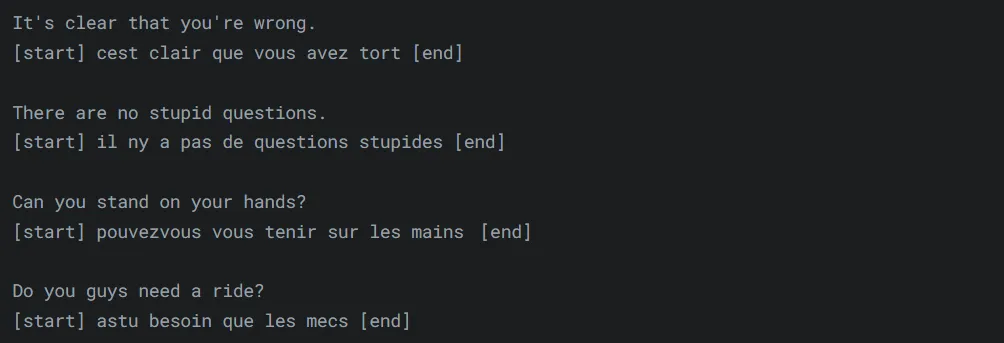
7. Use Cases 🚀
This section highlights various use cases for the Attention Is All You Need model, demonstrating its potential in practical applications.
One of the key use cases for this model is Language Translation, where it can be trained to translate between different languages.
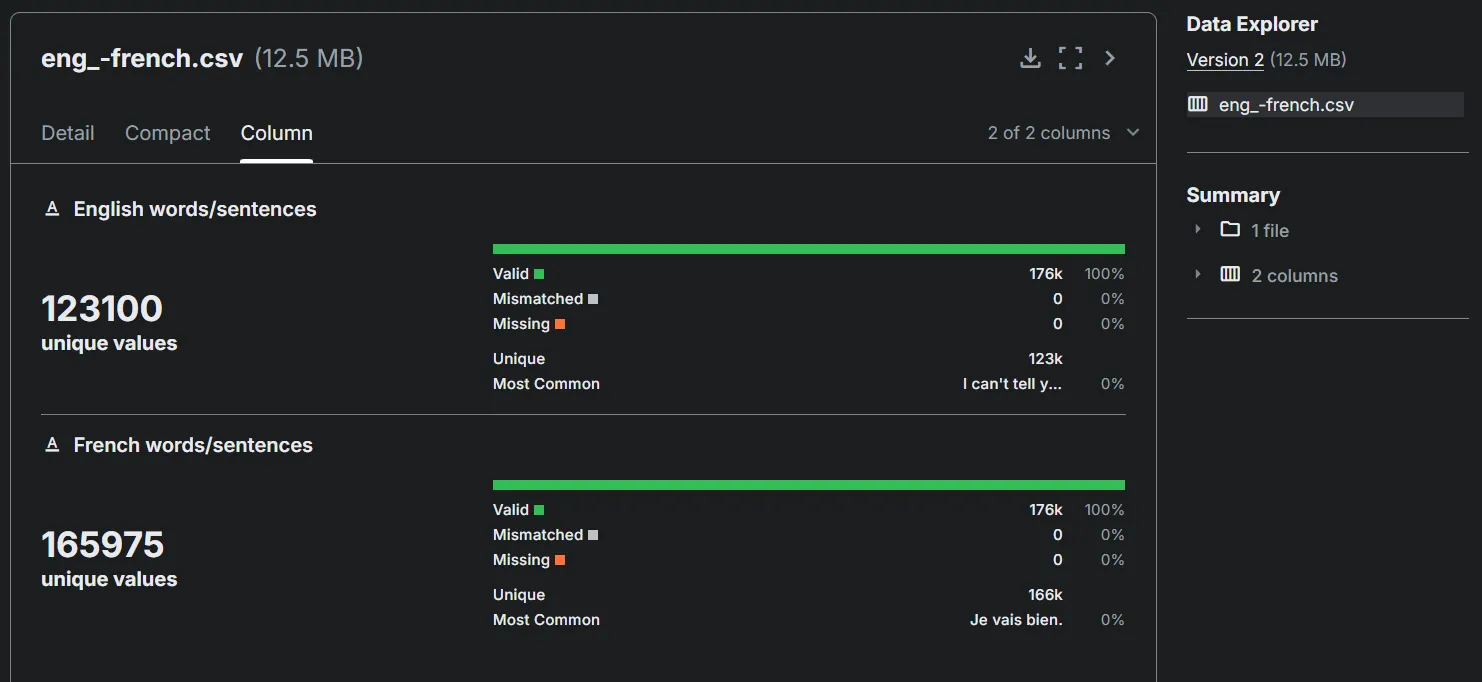
Dataset 📂
For training and evaluating the model, we use the English-French Language Translation Dataset from Kaggle. This dataset provides parallel English-French sentences for machine translation tasks.
Dataset Overview:
-
Content: The dataset consists of pairs of sentences in English and their corresponding French translations. This is a great resource for training models on language translation tasks.
-
Format: The dataset is provided in .csv format, containing two columns: one for the English sentence and the other for the French translation.
-
Size: The dataset contains approximately 10,000 pairs of English-French sentences, ideal for training a translation model.
How to Use the Dataset:
- Download the Dataset:
- Go to the Kaggle page and download the dataset.
- If you don’t have a Kaggle account, you need to create one and accept the dataset’s terms of use.
- Dataset Structure:
- The dataset contains the following columns:
- English: The sentence in English.
- French: The corresponding translation in French.
8. References 📚
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. A., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. Link

Thank you for taking the time to read. I hope you enjoyed reading it. I assume this article has provided valuable insights and sparked your curiosity about the Transformers. Stay tuned for more thought-provoking content and exciting advancements in the related field.
Keep Exploring, Keep Learning, and Keep Embracing the possibilities of AI!
If you liked this article ❤, feel free to share your views at any of my socials.
Follow me on my socials!