
Hello everyone! 👋
→ As you all know, The AI revolution is accelerating, and large language models (LLMs) are at the forefront. While proprietary models like OpenAI’s GPT-4 and Google’s Gemini dominate, the rise of powerful open-source alternatives is shifting the landscape. DeepSeek LLM is one such game-changer — a cutting-edge, open-source LLM that offers state-of-the-art capabilities without the constraints of closed ecosystems.
→ For the past couple of days, people (esp. AI communities) have been going crazy over the new release of the open-weight model **[DeepSeek-R1]**🐋, which matches [GPT-o1] in performance despite having a much lower training cost.
So, In today’s blog, I will be discussing the key takeaways that I have noted down while reading the DeepSeek-R1 Paper.
But before that if someone thinks the blog is too long, don’t have time to read it all! Then, here’s a quick summary of DeepSeek-R1 for you. Check below:
TL;DR 📄
DeepSeek R1 🐋 is a new large language model (LLM) released by a Chinese AI research team. DeepSeek R1 is explicitly designed as a “reasoning model”. It’s remarkable to say that the reasoning model is going to drive key advancement in large model progress in 2025.
-
RL-only training: R1-Zero was trained purely with reinforcement learning, showing that reasoning capabilities can emerge without pre-labeled datasets or extensive human effort.
-
Performance: R1 matched or outperformed OpenAI’s O1 on many reasoning tasks, though O1 dominated in coding benchmarks (4/5).
-
More time = Better results: Longer reasoning chains (test-time compute) lead to higher accuracy, reinforcing findings from previous studies.
-
Prompt Engineering: Few-shot prompting degrades performance in reasoning models like R1, echoing Microsoft’s MedPrompt findings.
-
Open-source: DeepSeek open-sourced the models, training methods, and even the RL prompt template, available in the paper and on PromptHub.
TABLE OF CONTENTS:
- Reinforcement Learning
- Preview of Paper
- Training Methodology (DeepSeek-R1-Zero & DeepSeek-R1)
- An Aha Moment of DeepSeek-R1-Zero
- Cold Start, CoT-(Chain of Thought) & Distillation
- Benchmarks
- Hot Takes from the AI Community on DeepSeek-R1
Disclaimer: First things first, In this blog, I won’t be going behind the Maths of the paper. I will just give a theoretical view of the paper.
PAPER: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning

OKAY! LET’S STARTTT >>> 3..2..1 🚀
Before we go deep dive into the paper, First we should know about RL - (Reinforcement Learning) which has a key role in this paper.
So, Let’s see what that means:
1. REINFORCEMENT LEARNING
→ Reinforcement Learning (RL) is a subset of machine learning that allows an AI-driven system (sometimes referred to as an agent) to learn through trial and error using feedback from its actions.
This feedback is either negative or positive, signaled as punishment or reward with, of course, the aim of maximizing the reward function.
💡Basic Idea
The basic idea behind a reinforcement learning agent is to learn from experience. Just like humans learn lessons from their past successes and mistakes, reinforcement learning agents do the same – when they do something “good” they get a reward, but, if they do something “bad”, they get penalized. The reward reinforces the good actions while the penalty avoids the bad ones.
Goal in RL: To select a policy that maximizes the expected return when the agent acts according to it.
Reinforcement learning requires several key components:
- Agent – This is the “who” or the subject of the process, which performs different actions to perform a task that has been assigned to it.
- Environment – This is the “where” or a situation in which the agent is placed.
- Actions – This is the “what” or the steps an agent needs to take to reach the goal.
- Rewards – This is the feedback an agent receives after performing an action.
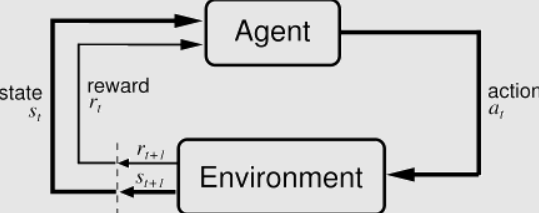
A Better way to understand RL with a real-life example:
Let’s say you’re in a park, trying to teach your dog to fetch a ball. In this case, the dog is the agent, and the park is the environment. Once you throw the ball, the dog will run to catch it, and that’s the action part. When he brings the ball back to you and releases it, he’ll get a reward (a treat). Since he got a reward, the dog will understand that his actions were appropriate and will repeat them in the future. If the dog doesn’t bring the ball back, he may get some “punishment” – you may ignore him or say “No!” After a few attempts (or more than a few, depending on how stubborn your dog is), the dog will fetch the ball with ease.
Okay! I guess that was enough to understand what RL- (Reinforcement Learning) stands for. Now, you are good to go. So, Let’s dive into the paper & see what it unfolds:
2. PREVIEW OF PAPER
→ DeepSeek-AI has released two first-generation reasoning models i.e. “DeepSeek-R1-Zero” and “DeepSeek-R1”
-
DeepSeek-R1-Zero: A pure RL-based model that achieves impressive reasoning capabilities without relying on supervised fine-tuning (SFT).
However, it encounters challenges such as poor readability, and language mixing. To address these issues and further enhance reasoning performance, they introduce DeepSeek-R1.
-
DeepSeek-R1: A more refined version that integrates multi-stage training and cold-start data to improve readability and reasoning performance.
This paper is taking the first step toward improving language model reasoning capabilities using pure reinforcement learning (RL).
🎯 Goal of the paper/authors: To explore the potential of LLMs to develop reasoning capabilities without any supervised data, focusing on their self-evolution through a pure RL process.
- Base Model used in the paper: DeepSeek-V3-Base
3. TRAINING METHODOLOGY
→ In the following sections, we will discuss the training methodology of:
-
DeepSeek-R1-Zero: which applies RL directly to the base model without any SFT data.
-
DeepSeek-R1: which applies RL starting from a checkpoint fine-tuned with thousands of long Chain-of-Thought (CoT) examples.
a. DeepSeek-R1-Zero (The no-SFT Model)
→
Technique: Group Relative Policy Optimization (GRPO) introduced by DeepSeek in the DeepSeekMath Paper — a technique in RL that builds upon the Proximal Policy Optimization (PPO) framework, designed to improve mathematical reasoning capabilities while reducing memory consumption.
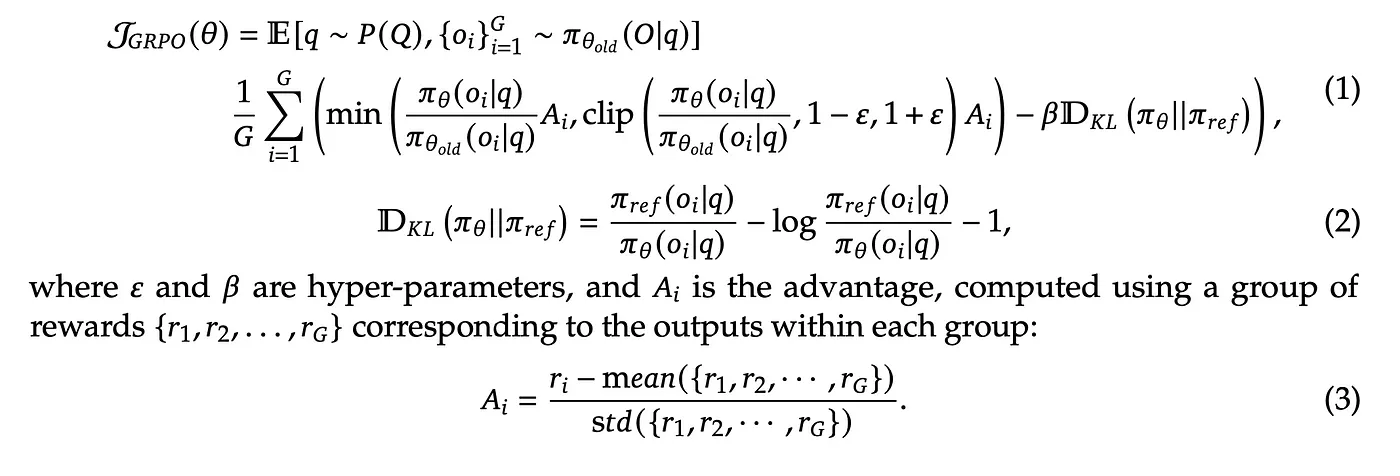
→ Traditional RL methods like PPO require two neural networks: an “actor” to generate responses and a “critic” to evaluate them. GRPO replaces the critic with statistical comparisons. For each problem, it generates multiple candidate solutions, then calculates rewards relative to the group’s average performance.
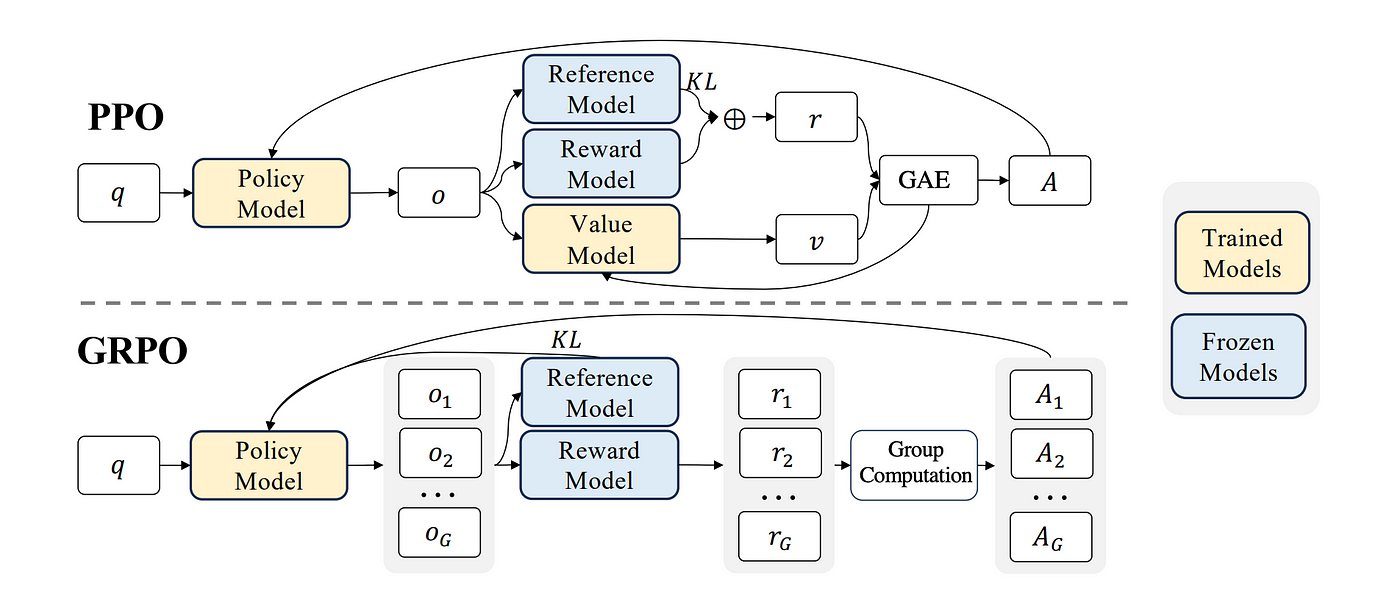
→ GRPO modifies the traditional Proximal Policy Optimization (PPO) by eliminating the need for a value function model, thereby reducing memory and computational complexity. Instead, GRPO uses group scores to estimate the baseline, simplifying the training process and resource requirements.
To know more about the algorithm, you can check out the details from the DeepSeekMath paper: https://arxiv.org/pdf/2402.03300
Reward Modelling:
→ DeepSeek-R1-Zero relied entirely on a rule-based reward system, which mainly consisted of two types:
- Accuracy rewards: The accuracy reward model evaluates whether the response is correct.
- Format rewards: rewards to enforce the model to put its thinking process between ‘< think >’ and ‘< /think >’ tags.
The authors did not apply the outcome or process neural reward model in developing DeepSeek-R1-Zero, because they found that the neural reward model may suffer from reward hacking in the large-scale reinforcement learning process, and retraining the reward model needs additional training resources and it complicates the whole training pipeline.
Training Template:
→ For a conversational-style LLM, a question-and-response template is typically required. Surprisingly, the prompt template for DeepSeek-R1-Zero is quite simple.

Performance and Reasoning:
→ During training, DeepSeek-R1-Zero has developed sophisticated reasoning behaviors such as reflection — where the model revisits and re-evaluates its previous steps — and the exploration of alternative approaches to problem-solving.
They also observed the “self-evolution” process of DeepSeek-R1-Zero over the course of training where the average response length has increased steadily. In other words, R1-Zero learns to spend more time thinking, effectively reflecting the scaling law of test-time-computation.
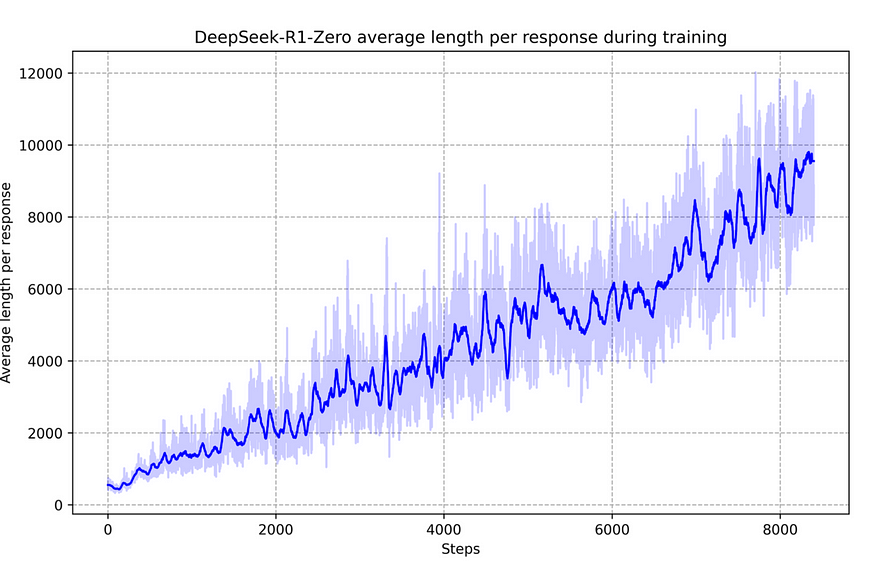 Fig: The average response length of DeepSeek-R1-Zero on the training set during the RL process.
Fig: The average response length of DeepSeek-R1-Zero on the training set during the RL process.
DeepSeek-R1-Zero has impressive performance despite being only trained with Reinforcement Learning (RL).
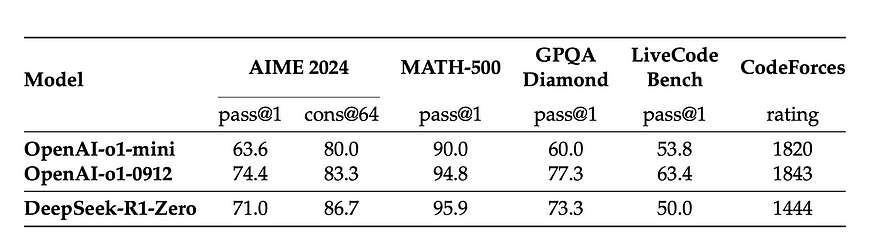 Table: Comparison of DeepSeek-R1-Zero and Open AI o1 models on reasoning-related benchmarks
Table: Comparison of DeepSeek-R1-Zero and Open AI o1 models on reasoning-related benchmarks
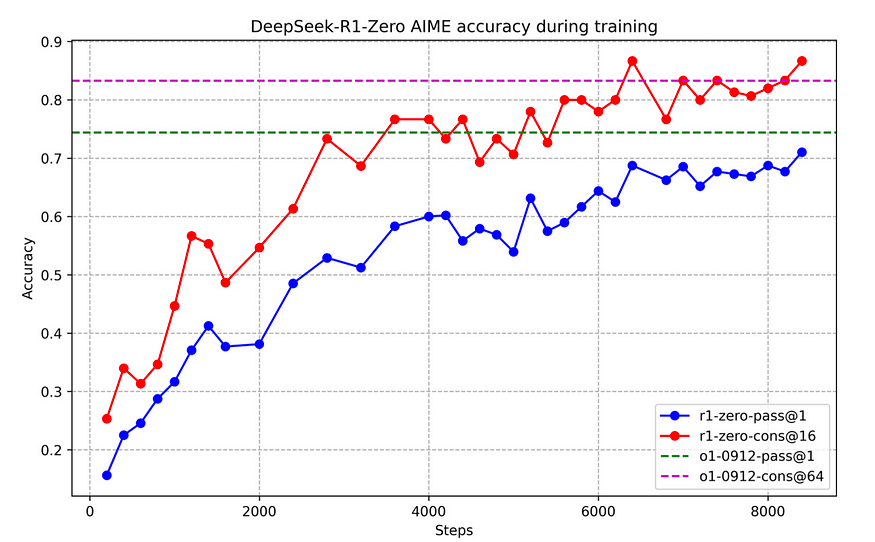 Fig: AIME accuracy of DeepSeek-R1-Zero during training
Fig: AIME accuracy of DeepSeek-R1-Zero during training
Nevertheless, R1-Zero does have some limitations, as mentioned earlier. It often struggles with issues like poor readability and language mixing. The introduction of DeepSeek-R1 aims to address these challenges.
Key Breakthrough — The “Aha” moment ✨
→ A particularly intriguing phenomenon observed during the training of DeepSeek-R1-Zero is the occurrence of an “aha moment”.

During training, the model learned to dynamically allocate more thinking time by re-evaluating its initial problem-solving approach. This was the “aha” moment for both the model and the researchers! Rather than explicitly teaching the model how to solve a problem, they simply provide it with the right incentives, and it autonomously develops advanced problem-solving strategies. A powerful reminder of the potential of RL to unlock new levels of intelligence in artificial systems.
b. DeepSeek-R1
→ DeepSeek-R1 aims to improve from the Zero by incorporating a multi-stage post-training process. The training of DeepSeek-R1 was split into 4 stages:
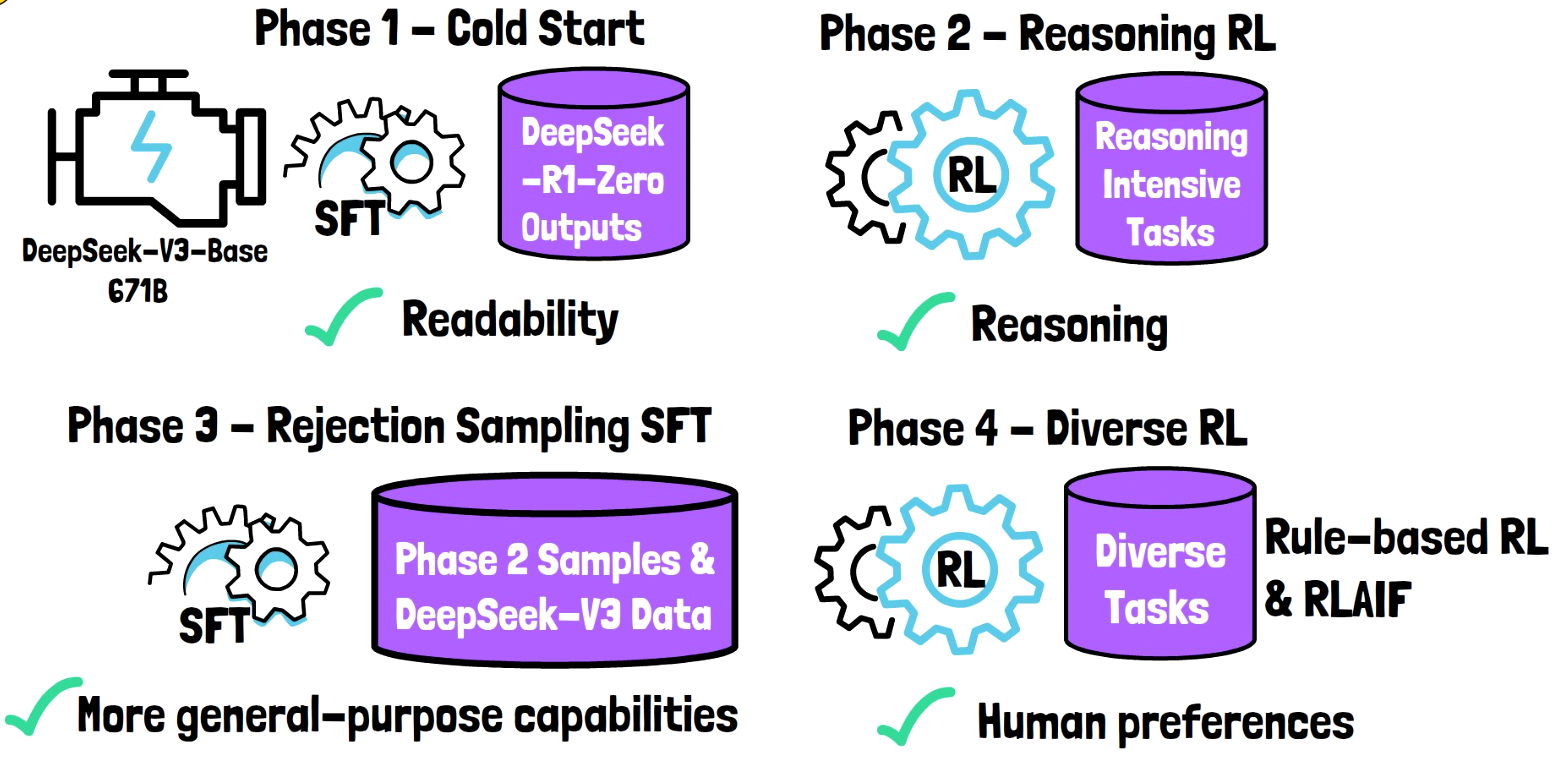
STAGE-1: Cold Start
Collect a small amount of long Chain-of-Thought (CoT) data. Data collection methods:
- Few-shot prompting with long CoT example
- Direct prompting for detailed answers with reflection
- Gathering DeepSeek-R1-Zero outputs in a readable format
STAGE-2: Reasoning-Oriented Reinforcement Learning
- Similar to the DeepSeek-R1-Zero approach
- Added reward: Language consistency reward — measures the proportion of target language words in Chain-of-Thought
STAGE-3: Rejection Sampling and Supervised Fine-Tuning
- Occurs after reasoning-oriented RL converges
- Collect data to enhance: Writing capabilities, role-playing skills, general-purpose task performance
STAGE-4: Comprehensive Reinforcement Learning
- Secondary RL stage focusing on: Improving model helpfulness, enhancing harmlessness, refining reasoning capabilities
Few Technical Terms explained in the paper:
i. What is Cold Start?
→ Cold start involves fine-tuning the base model(DeepSeek-V3-Base) with curated long Chain-of-Thought (CoT) data to stabilize RL training. This process ensures:
- Enhanced readability.
- Structured responses with summaries at the end of each output.
- To address the initial instability of RL training when starting with a raw, untuned model.
- It creates a foundation for RL to build upon, enabling faster convergence and better performance on reasoning tasks.
ii. What is CoT (Chain-of-Thought)?
→ Chain-of-Thought prompting is a technique that improves the performance of language models by explicitly prompting the model to generate a step-by-step explanation or reasoning process before arriving at a final answer. This method helps the model to break down the problem and not skip any intermediate tasks to avoid reasoning failures.
→ CoT is effective because it helps focus the attention mechanism of the LLM. The decomposition of the reasoning process makes the model focus its attention on one part of the problem at a time, minimizing the risk of errors that might arise from handling too much information simultaneously.
Let’s see one of the examples:
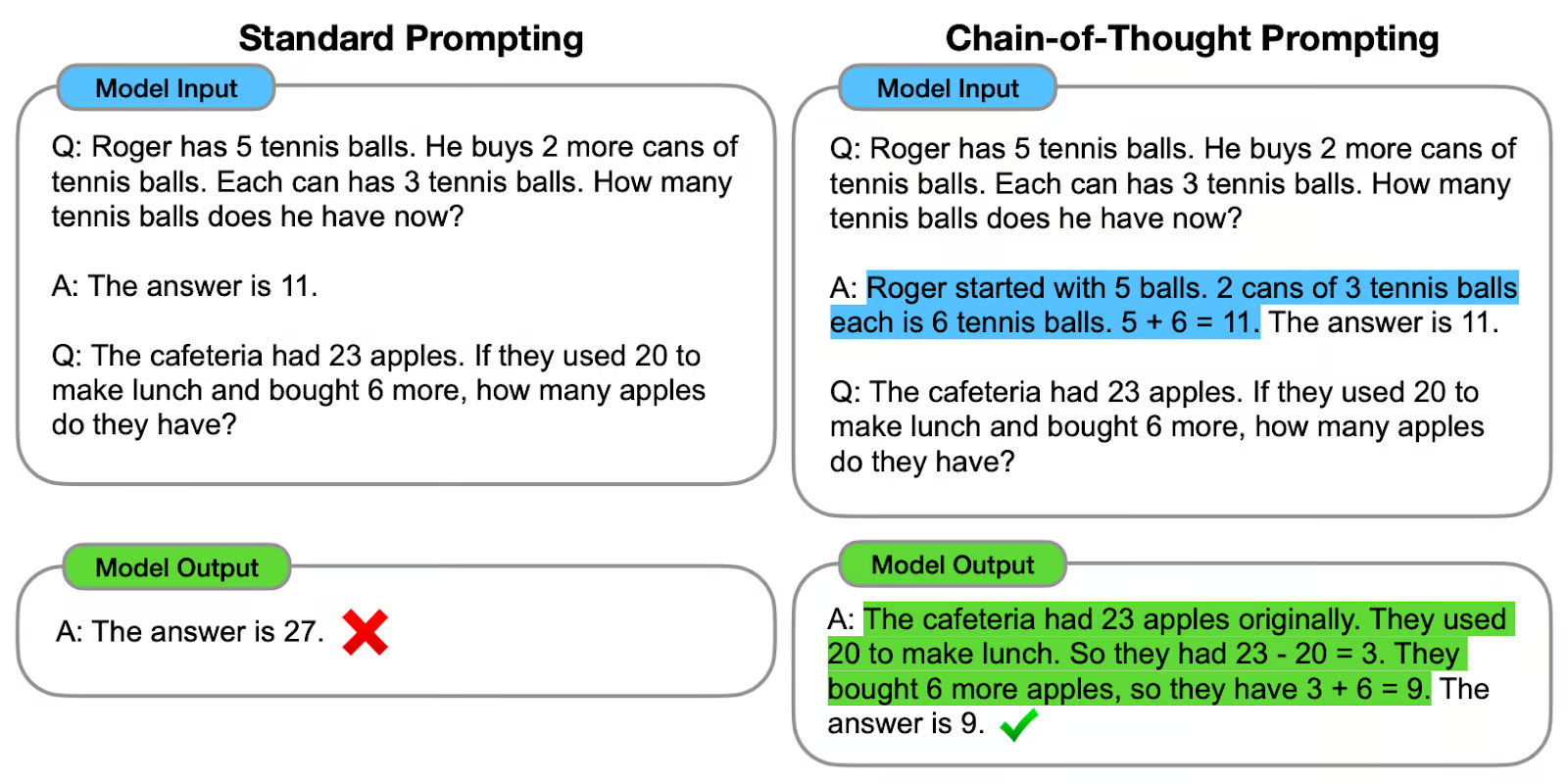
This technique is highly effective because it breaks down complex problems into more manageable parts. The approach allows models to focus on solving each part step-by-step, which boosts their accuracy.
iii. What is Distillation?
→ DeepSeek employs distillation techniques to transfer the knowledge and capabilities of larger models into smaller, more efficient ones. This makes powerful AI accessible to a wider range of users and devices.
→ It’s like a teacher transferring their knowledge to a student, allowing the student to perform tasks with similar proficiency but with less experience or resources.
→ DeepSeek’s distillation process enables smaller models to inherit the advanced reasoning and language processing capabilities of their larger counterparts, making them more versatile and accessible.
4. BENCHMARKS PERFORMANCE OF DEEPSEEK-R1
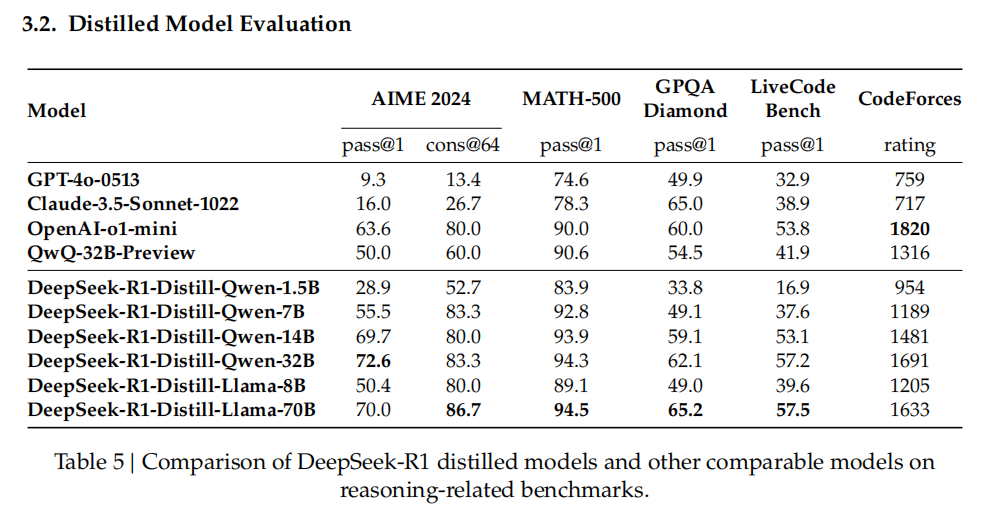
→ DeepSeek-R1 achieves performance comparable to OpenAI-o1-1217 on reasoning tasks. To support the research community, they open-source DeepSeek-R1-Zero, DeepSeek-R1, and six dense models (1.5B, 7B, 8B, 14B, 32B, 70B) distilled from DeepSeek-R1 based on Qwen and Llama.
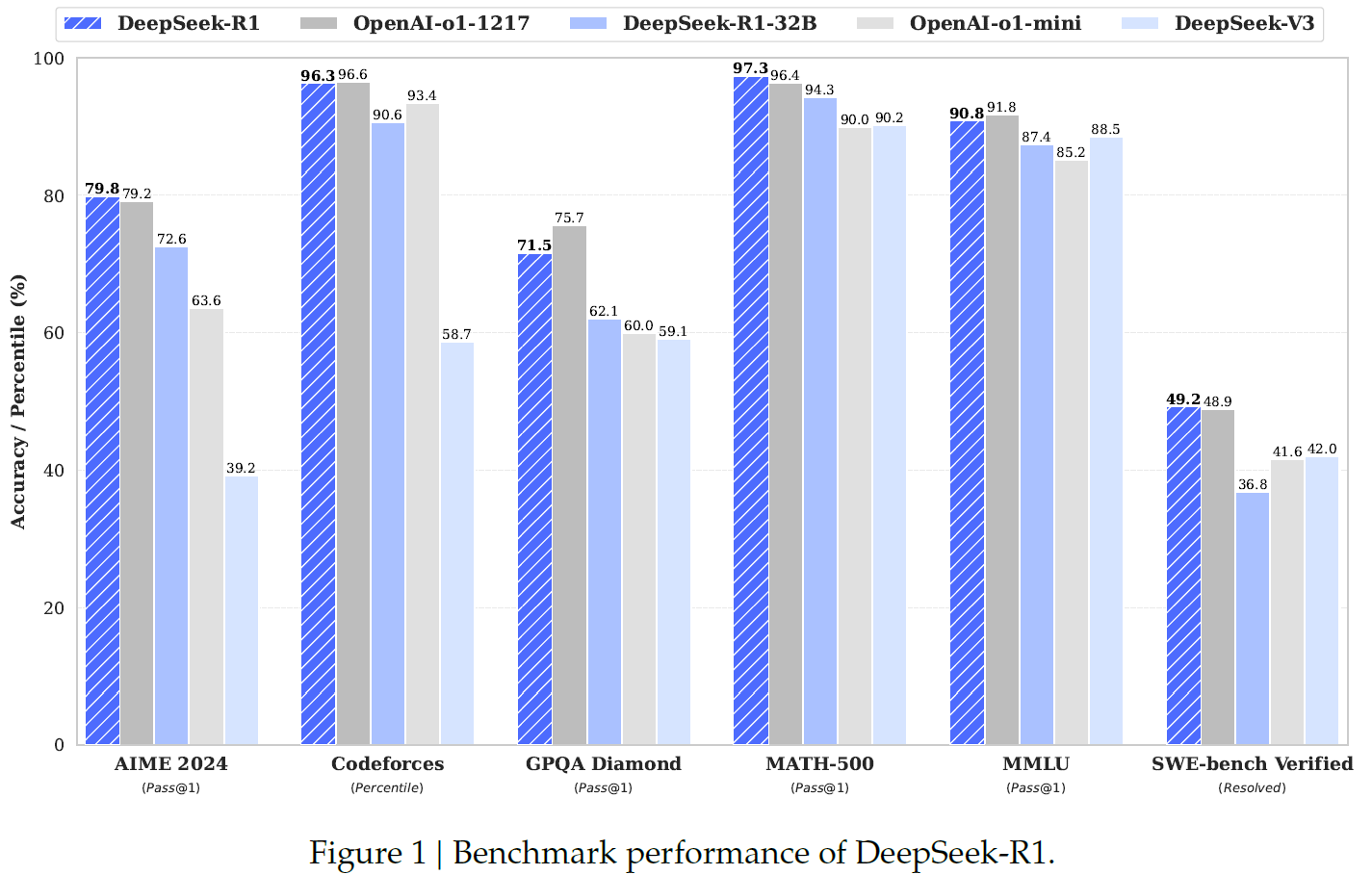
→ DeepSeek-R1 got a score of 79.8% Pass@1 on AIME 2024, slightly surpassing OpenAI-o1–1217. On MATH-500, it attains an impressive score of 97.3%, performing on par with OpenAI-o1–1217 and significantly outperforming other models.
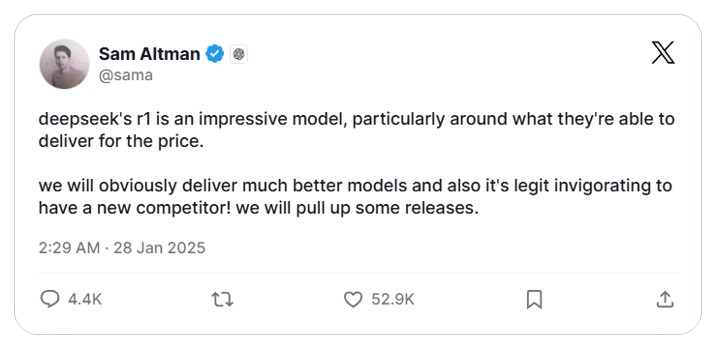
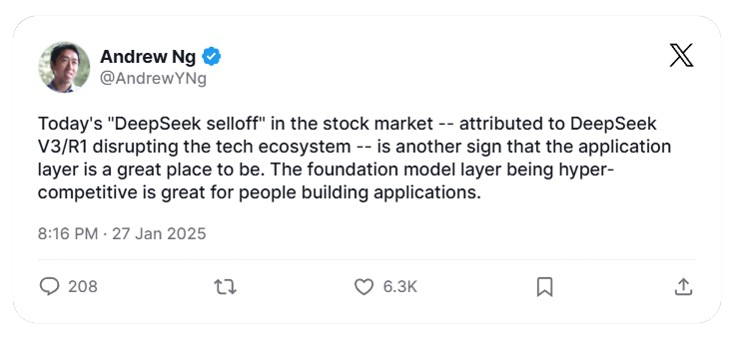
5. HOT TAKES FROM THE AI COMMUNITY ON DEEPSEEK-R1 🐋
→ Here are some snapshots of the views of the people of AI Communities.
- Sam Altman - CEO of OpenAI
b. Andrew Ng - Founder of DeepLearning.AI
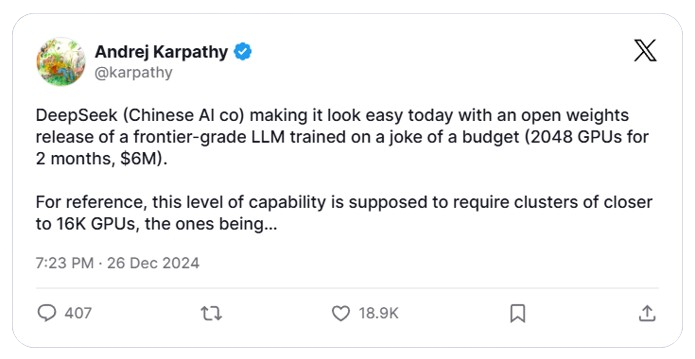
c. Andrej Karpathy - Computer Scientist (previously @Tesla, @OpenAI)
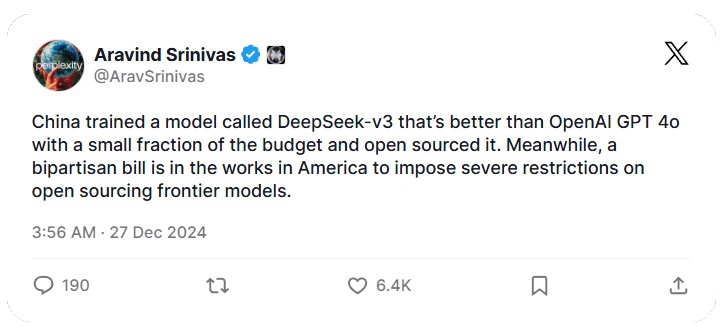
d. Aravind Srinivas - CEO of Perplexity.AI
6. CONCLUDING NOTES
→ DeepSeek R1 represents a significant milestone in the evolution of artificial intelligence. Its combination of advanced reasoning capabilities, innovative training methods, and commitment to accessibility sets new standards for AI development. As the technology continues to evolve, its impact on various industries and research fields will likely grow.
→ This is not all Deepseek has. If they could manage an o1-level model within a month of v3, I expect much more to be in the pipeline. They might release an o1-pro beating model in the next few months, and nobody will be surprised if they do that.
Yup, THAT’s IT. Thank you for taking your precious time here. I hope you enjoyed reading about the DeepSeek-R1! Questions or any comments? Drop it below — because learning is always better when it’s a two-way street. 🚀
If you liked this article ❤, feel free to drop your views at any of my socials.
Follow me on my socials!
References:
1. https://arxiv.org/abs/2501.12948
2. https://youtu.be/XMnxKGVnEUc
3. https://www.opit.com/magazine/reinforcement-learning-2/
4. https://www.philschmid.de/deepseek-r1
5. https://medium.com/@namnguyenthe/deepseek-r1-architecture-and-training-explain-83319903a684
6. https://medium.com/@mayadakhatib/deepseek-r1-a-short-summary-73b6b8ced9cf
7. https://aipapersacademy.com/deepseek-r1/
8. https://abhishek-maheshwarappa.medium.com/deepseek-r1-revolutionizing-reasoning-with-reinforcement-learning-and-distillation-24f9e1877627