
Introduction
In a world where artificial intelligence (AI) is transforming how we communicate, learn, and work, most language models are built with English or a handful of global languages in mind. This leaves millions of people, especially in linguistically diverse regions like India, underserved. Sarvam AI, a pioneering Indian startup focused on building a sovereign AI ecosystem for India, has taken a bold step to address this gap with Sarvam-M, a hybrid reasoning model designed specifically for Indic languages.
This blog post explores the development, performance, and potential impact of Sarvam-M, drawing insights from Sarvam AI’s technical blog. (Sarvam AI Blog)
🤖 What is Sarvam-M?
Sarvam-M is a large language model (LLM) designed to serve India’s diverse linguistic landscape, supporting 10 major Indian languages—Hindi, Bengali, Gujarati, Kannada, Malayalam, Marathi, Oriya, Punjabi, Tamil, and Telugu—which collectively cover about 70% of the country’s population. Built on the 24-billion parameter Mistral Small framework and licensed under Apache 2.0, Sarvam-M is tailored to excel not only in native scripts but also in code-mixed and romanized forms, making it highly adaptable to real-world communication patterns in India. In addition to its linguistic capabilities, the model is optimized for tasks such as coding, math, and culturally relevant reasoning, positioning it as a powerful and versatile tool for education, technical innovation, and diverse use cases across the country.
The model is accessible to the public in multiple ways:
- Download: Available on Hugging Face (Hugging Face).
- Playground: Test it interactively on Sarvam AI’s dashboard (Sarvam Playground).
- APIs: Developers can integrate it into applications via APIs (Sarvam API Docs).
🧪 The Development of Sarvam-M
Creating a model like Sarvam-M required a sophisticated blend of data curation, fine-tuning, and optimization. Here’s a breakdown of the key processes involved:
- Supervised Fine-Tuning (SFT)
- Reinforcement Learning with Verifiable Rewards (RLVR)
- Inference Optimizations
1. Supervised Fine-Tuning (SFT) 🎯
To make Sarvam-M proficient in Indic languages and specialized tasks, Sarvam AI undertook an extensive supervised fine-tuning process:
-
Prompt Curation:
The team started with 11.5 million prompts, which were deduplicated to 7 million and further filtered to 5.2 million high-quality prompts. These were clustered into 100,000 groups using advanced tools like FAISS (FAISS GitHub) and Alibaba’s gte-Qwen2-7B-instruct model (Alibaba Model). -
Quality and Difficulty:
A custom scorer evaluated prompts for quality (61.31% excellent, 32.98% good, 4.44% average, 1.27% poor, 0.01% very poor) and difficulty (6.11% very hard, 44.45% hard, 28.45% medium, 20.13% easy, 0.86% very easy). -
Language Distribution:
About 30% of prompts focused on coding, math, and reasoning, with 50% of the remaining prompts translated into Indic languages. Hindi accounted for 28% of the dataset, while nine other regional languages each contributed 8%. Prompts were formatted in native scripts (50%), code-mixed (25%), and romanized (25%) forms. -
Training Strategy:
The model was trained in two phases—two epochs in “non-think” mode (direct response generation) and two epochs in “think” mode (reasoning with<think>tokens)—before merging the results using the Slerp algorithm.
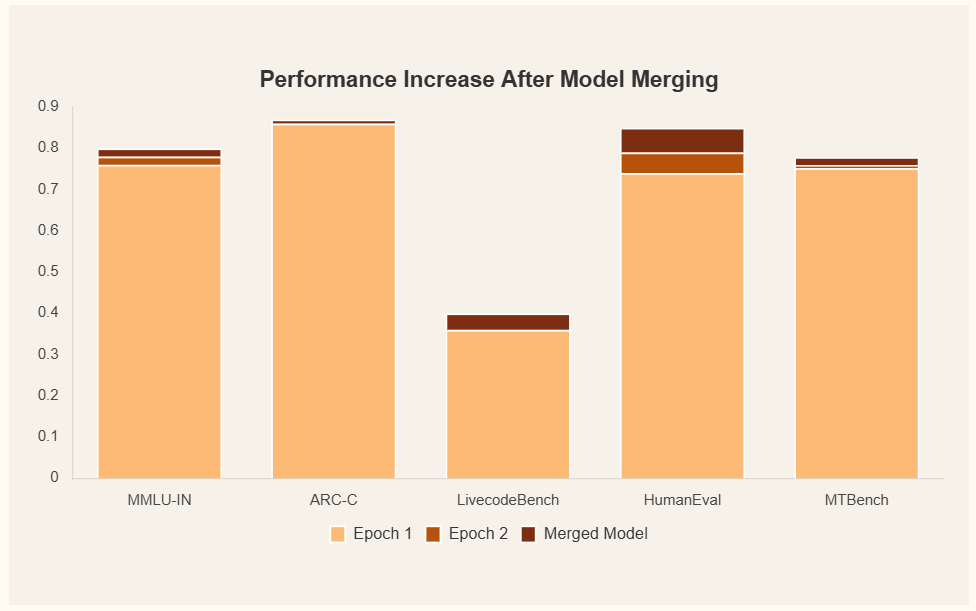
2. Reinforcement Learning with Verifiable Rewards (RLVR) ♻️
To further enhance Sarvam-M’s capabilities, Sarvam AI employed reinforcement learning with verifiable rewards (RLVR):
-
Curriculum:
The training focused on math (GSM8K, MATH, Big Math), instruction following (Extended IFEval), code understanding (Synthetic-1), code generation (PrimeIntellect subset), and translation. The dataset was balanced with 40% English, 40% Indic native, and 20% Indic romanized prompts. -
Reward Structures:
Unlike traditional human feedback, RLVR used hard metrics like test case results for code and mathematical checks. Learning rates were set at 3e-7 for general tasks and 2e-7 for math and code, with a ~20% pass-through rate for prompts.
3. Inference Optimizations ⚙️
To ensure Sarvam-M performs efficiently in real-world applications, the team implemented several optimizations:
-
FP8 Quantization:
The model was quantized from FP16 to FP8 using TensorRT-LLM, reducing memory usage and boosting inference speed.- Hardware Configurations: Optimized for H100 GPUs, supporting high concurrency (~100 tokens/second/stream) and low concurrency (~300 tokens/second/stream) scenarios. -
Wikipedia RAG:
A retrieval-augmented generation (RAG) system using Wikipedia, enhanced with bge-multilingual-gemma2 embeddings, improved recall by 35%. This led to a dramatic increase in SimpleQA accuracy from 5% to 72% in English and 59% in Indic languages (SimpleQA-IN).
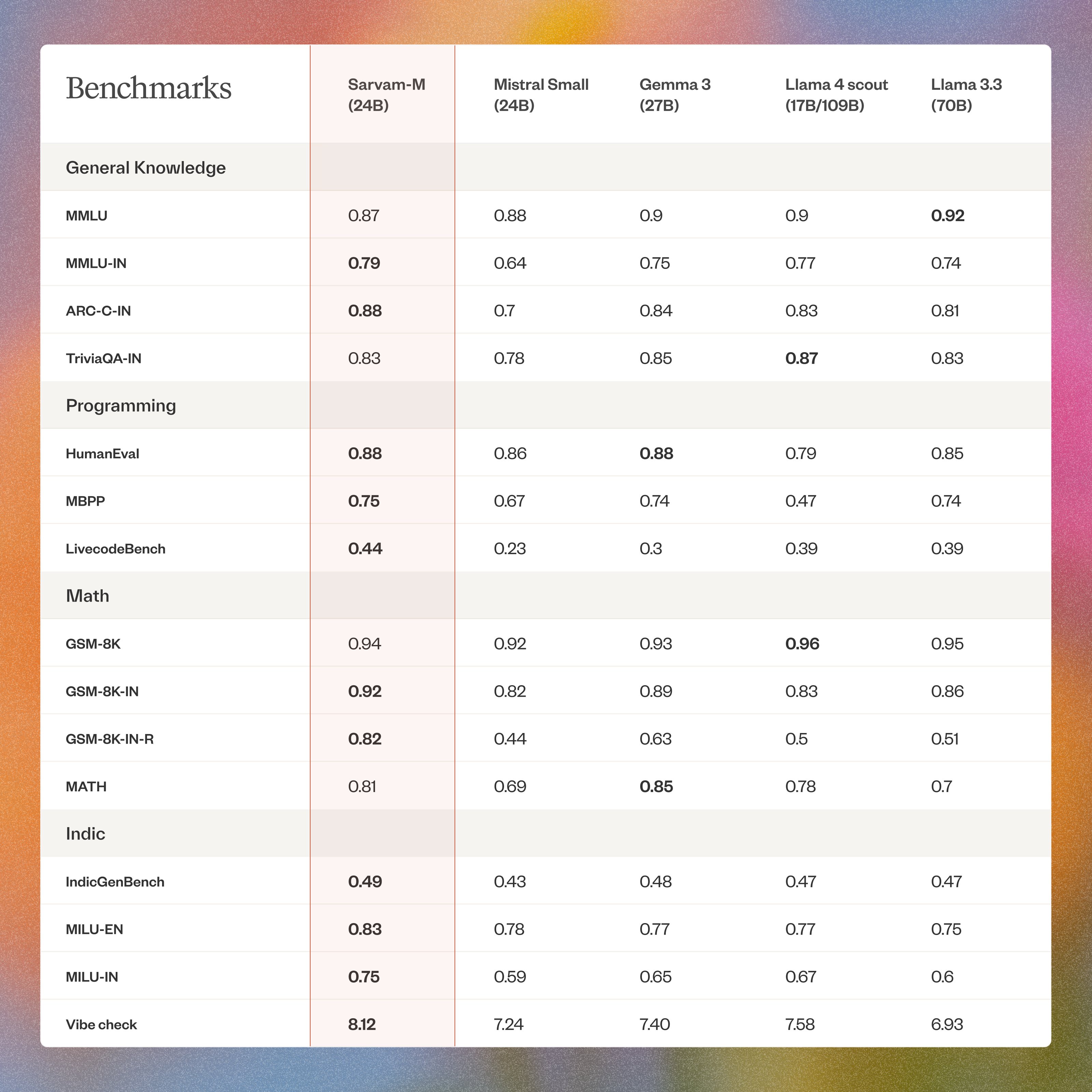
📊 Benchmarks Highlights
The benchmark comparison evaluates the performance of several large language models - Sarvam-M (24B), Mistral Small (24B), Gemma 3 (27B), Llama 4 scout (17B/109B), and Llama 3.3 (70B)—across diverse categories: General Knowledge, Programming, Math, Indic languages, and an overall “Vibe Check.” Sarvam-M emerges as the most well-rounded performer, particularly excelling in India-centric tasks such as MMLU-IN, ARC-C-IN, and MILU-IN, as well as dominating programming benchmarks like MBPP and LivecodeBench. Llama 3.3 leads global general knowledge tasks (MMLU), while Llama 4 Scout tops in math benchmarks like GSM-8 K. Gemma 3 holds strong in math and programming, especially on the MATH dataset. Sarvam-M also secures the highest Vibe Check score, indicating a balanced and user-aligned model experience. In contrast, Mistral Small lags behind most models across categories.
⚖️ Comparisons:
- Sarvam-M (24B) is the top performer in Indian-specific tasks, leading in MMLU-IN, ARC-C-IN, MILU benchmarks, and all Indic language tests.
- It also dominates programming benchmarks, topping HumanEval (tied), MBPP, and LivecodeBench.
- Llama 3.3 (70B) is strongest in global general knowledge (MMLU), while Llama 4 Scout leads in math reasoning (GSM-8K).
- Gemma 3 performs well in math-heavy tasks, particularly excelling in the MATH dataset.
- Sarvam-M earns the highest “Vibe Check” score (8.12), indicating a well-balanced, user-friendly experience, while Mistral Small consistently lags across benchmarks.
🧱 Challenges and Lessons Learned
Developing Sarvam-M was not without its hurdles. One significant challenge was the low initial adoption rate, with only 334 downloads in the first two days on Hugging Face, compared to a Korean model’s 200,000 downloads (Analytics India Mag). Investor Deedy Das called this response “embarrassing,” arguing there was little audience for such incremental work, especially with more advanced models from Google and TWO.ai available.
Despite raising $41 million and being valued at $111 million (Sarvam AI Series A), some critics felt Sarvam AI’s contributions did not match the funding. Technically, while Sarvam-M excelled in Indian language and math tasks, it saw a 1% decline in English knowledge evaluations like MMLU, highlighting trade-offs in specializing in Indic languages.
The need for extensive Indic language data collection posed another challenge, as large-scale datasets are resource-intensive to curate. Community feedback was mixed, with some defending Sarvam-M’s methodology and others questioning the nationalism angle. Comparisons with other government-backed models, like BharatGen’s Param-1-1 with only 12 downloads (AIKosh), underscored similar adoption challenges.
Lessons learned include the importance of user engagement, clear communication of the model’s value, and the need for more extensive pre-training to balance Indic and English performance. These insights are crucial for future iterations and demonstrate Sarvam AI’s commitment to transparency.
🚀 The Future of AI in India
Sarvam-M is a cornerstone in building a sovereign AI ecosystem for India, aligning with Sarvam AI’s vision to make India an active participant in AI development, not just a consumer. Leveraging India’s strengths—government-led digital public goods like Aadhaar and UPI, a growing developer community, and ROI-focused enterprises—Sarvam AI is creating AI solutions tailored to India’s unique needs.
The company is developing a comprehensive Generative AI stack, including:
- Foundational models for Indian languages and reasoning.
- Cloud and edge platforms.
- Applications like Conversational and Reasoning Agents.
Supported by MeitY’s IndiaAI Mission and in collaboration with IIT Madras, Sarvam AI is fostering innovation through open-source initiatives and the Sarvam Circle, inviting global collaboration for research, custom models, technical education, and impact sector applications.
Sarvam-M’s potential applications are transformative:
-
Education:
Creating personalized learning content and assessment tools in regional languages, such as the “Call a Teacher” application, which delivers conversational lessons based on NCERT textbooks (Forbes India). -
Healthcare:
Understanding medical terminology and providing accurate text-to-speech for patient communication, enhancing telemedicine, and AI-driven healthcare assistants. -
Governance:
Partnering with government agencies to improve public services, making them more accessible in native languages (Medium).
As Sarvam AI continues to refine its models, the future of AI in India looks promising, with the potential to bridge digital divides, foster innovation, and drive economic growth.
Conclusion
Sarvam-M is more than a technical achievement; it’s a step toward making AI inclusive and relevant for India’s diverse population. Its open accessibility, robust performance, and focus on Indic languages position it as a catalyst for innovation. As Sarvam AI continues to refine and expand this model, it promises to reshape how AI serves one of the world’s most linguistically rich regions.
📚 Key Citations:
1. Sarvam AI Blog: Explorations in Post Training and Inferencing Optimizations
2. Sarvam-M Model on Hugging Face
3. Sarvam AI Playground for Testing Sarvam-M
4. Sarvam AI API Documentation
5. FAISS GitHub for Clustering Prompts
6. Alibaba gte-Qwen2-7B-instruct Model
7. Indic Evals Collection on Hugging Face
8. Open Sourcing R1-theory of the case